摘要:
mysql in会使用索引吗?是的,MySQL会使用索引来加快数据查询和数据检索的速度。索引能够帮助数据库系统快速定位到存储数据的位置,从而提高数据的检索效率。当查询语句包含查询条...
摘要:
mysql in会使用索引吗?是的,MySQL会使用索引来加快数据查询和数据检索的速度。索引能够帮助数据库系统快速定位到存储数据的位置,从而提高数据的检索效率。当查询语句包含查询条... mysql in会使用索引吗?
是的,MySQL会使用索引来加快数据查询和数据检索的速度。索引能够帮助数据库系统快速定位到存储数据的位置,从而提高数据的检索效率。
当查询语句包含查询条件时,MySQL会根据索引快速定位到符合条件的数据行,大大减少了数据扫描的时间。因此,在设计数据库表时,合理创建索引是提高MySQL查询性能的重要手段之一。但是,过多的索引也会导致查询性能下降,因此需要根据实际情况进行适当的索引设计和优化。
mysql查询in为什么用不上索引?
1.mysql查询in用不上索引,说明查询语句本身有问题。
2.MySQL是查询语句,最好用Access2010来操作。
3.查询是用来操作数据库中的记录对象,利用它可以按照预先定义的不同条件从数据表或其它查询中筛选出需要操作的字段,并可以把它们集中起来,形成动态数据集。用户可以浏览、查询、打印,甚至修改这个动态数据集中的数据。
4.通过查询,可以查找和检索满足指定条件的数据,包括几个表中的数据,也可以使用查询同时更新或删除几个记录,以及对数据执行预定义或自定义的计算。
5.使用查询可以回答有关数据的特定问题,而这些问题通过表很难解决。可以使用查询筛选数据、执行数据计算和汇总数据。可以使用查询自动执行许多数据管理任务,并在提交数据更改之前查看这些更改。
6.查询实际上也就是选取记录的条件。查询出来的数据也存储到一个临时的表中。用于从表中检索数据或者进行计算的查询称为选择查询,用于添加、更改或删除的查询叫做操作查询。
mysql语句中in的字段过多怎么优化?
当使用多个字段进行IN子查询时,可以考虑将这些字段的值放入临时表中,并通过JOIN来优化查询性能。
首先创建临时表,然后将需要过滤的值插入临时表中,最后通过JOIN把临时表和原表连接起来进行查询。这样可以避免过多字段在IN子查询中造成性能下降的问题。同时,也可以考虑对需要过滤的字段进行索引优化,提高查询效率。
mysql in最好控制多少以内?
MySQL的最佳控制范围取决于多个因素,包括服务器硬件、应用程序负载和预算。一般来说,如果服务器的内存和处理器速度高,应用程序负载较轻,则MySQL可以在数百个连接下运行良好。然而,如果服务器资源受限,则需要适当降低连接数。此外,应该考虑负载均衡和缓存等技术来优化MySQL的性能。总的来说,最好的控制范围应该在50到300之间,具体取决于上述因素。
mysql中in嵌套select只能查询出一个结果?
没见过这么不严谨的写法…… 好吧,你每次执行WHERE id in (SELECT knowledge……)里面的数据的时候,括号里面都要执行一次。
可能就是因为这个原因导致的错误。具体不明。MySQL查询select * from table where id in (几百或几千个id) ,如何提高效率?
看了下面各位的回答,有的说用exist,有的说用join,难道你们不是在把简单的事情复杂化了吗?竟然还有子表子查询一说?也有朋友说的很精准,不要用select *,这个*是个坑,实际开发过程中,关于MySQL开发规范也会明确告知大家不要select *。
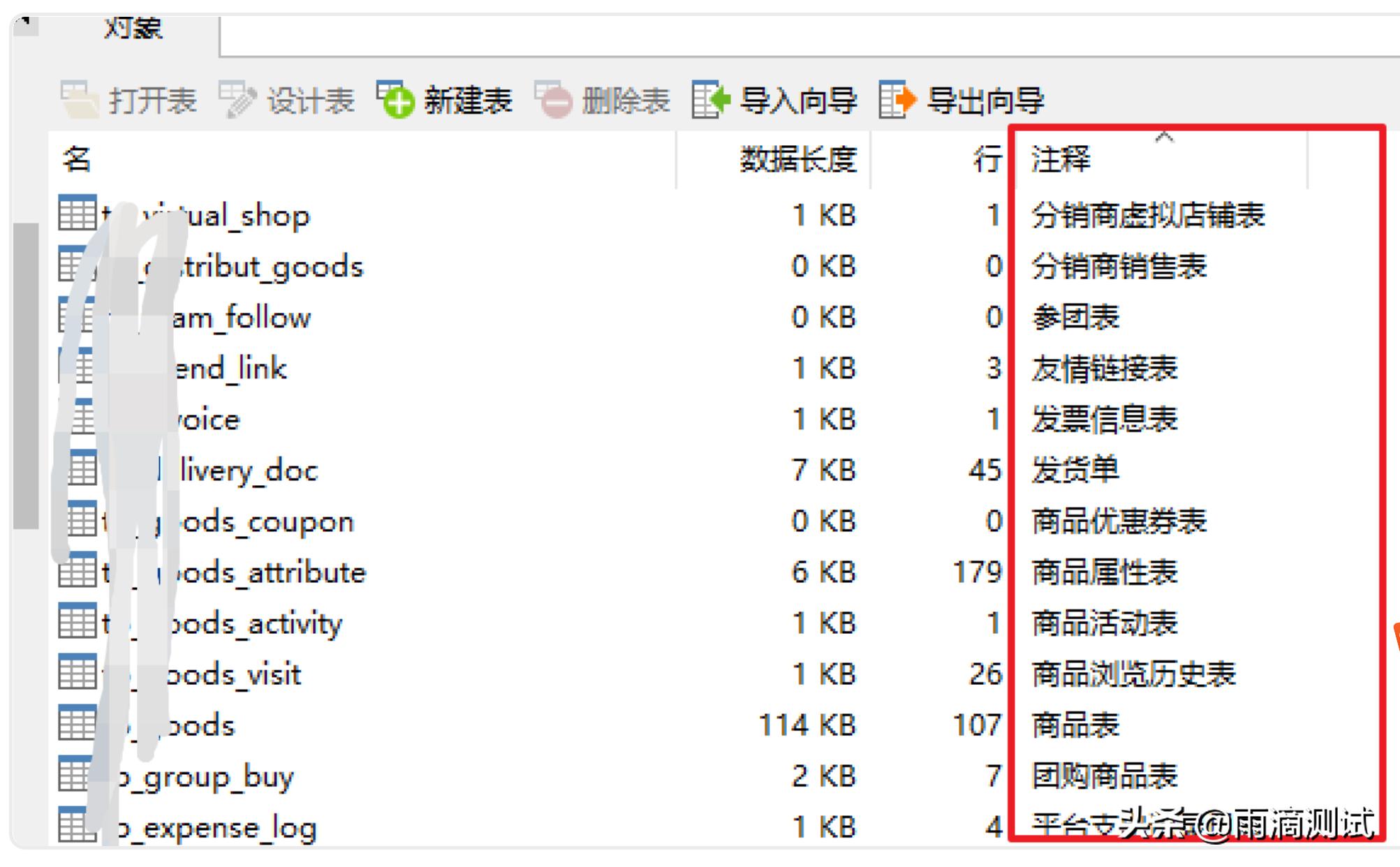
首先我想问的是:查询MySQL的一张表怎么查最快?当然是根据主键查询了!
默认你的MySQL库、表引擎是Innodb引擎,然后会有一颗主键的B+树,叶子节点就是这个主键索引对应的数据,意味着一次查询即可,回表都不需要好不好?简单直接!
这就是MySQL在Innodb引擎下的聚集索引。
什么是聚集索引?
InnoDB聚集索引的叶子节点存储行记录,因此InnoDB必须要有且只有一个聚集索引。
1.如果表定义了PK(Primary Key,主键),那么PK就是聚集索引。
2.如果表没有定义PK,则第一个NOT NULL UNIQUE的列就是聚集索引。
3.否则InnoDB会另外创建一个隐藏的ROWID作为聚集索引。
这种机制使得基于PK的查询速度非常快,因为直接定位的行记录。
下图是利用普通索引做查询时候的一个回表操作,如何避免回表操作?使用覆盖索引!即select xxx,yyy from table where xxx='' and yyy='',只能查询xxx,yyy就会避免回表操作!

所以你还搞什么其他各种操作来秀呢?只不过题主说了id不是连续的,所以做不到范围查询,也就无法between查询了。
不要纯粹的依赖数据库
如果这个查询量级很大,并发很高,原则上我们是不允许直接查库的,中间必须有一层缓存,比如Redis。那至于这个数据怎么存储到redis就要看具体业务具体分析了。
如果内存足够,甚至可以把这几十万的数据直接放到redis里面去,然后通过redis 的管道查询一次给批量查询出来。
如果没必要存储这么多,或者不让存这么多,是不是可以采用redis的淘汰策略来控制缓存里的数据都是热点数据?