摘要:
mysql很多重复的sql怎么处理?为了处理MySQL中的重复SQL,我们可以通过使用存储过程、函数或视图来避免重复的SQL代码。另外,可以利用索引和优化查询语句来提高数据库性能,...
摘要:
mysql很多重复的sql怎么处理?为了处理MySQL中的重复SQL,我们可以通过使用存储过程、函数或视图来避免重复的SQL代码。另外,可以利用索引和优化查询语句来提高数据库性能,... mysql很多重复的sql怎么处理?
为了处理MySQL中的重复SQL,我们可以通过使用存储过程、函数或视图来避免重复的SQL代码。另外,可以利用索引和优化查询语句来提高数据库性能,减少重复查询。
另外,可以考虑使用ORM框架来帮助管理SQL查询,以及将常用的SQL查询语句封装成可重用的方法。最后,通过对数据库的结构进行优化,避免冗余数据的存在,也能有效减少重复的SQL查询。
图片来源:网络
oracle数据库中如何用sql语句查出重复字段以及如何删除?
试试这个吧:把姓名改成数据库对应的姓名列名,table改为表名即可。select*fromtablewhere姓名in(select姓名fromtablegroupby姓名havingcount(姓名)>1)
SQL查询语句,怎样查询重复数据?
select id,count(1) 重复次数 from A group by id having count(1)>1;查询出来的结果都是id重复的,重复次数 中的数值就是重复了多少次。
一个表中有重复记录如何用SQL语句查询出来?
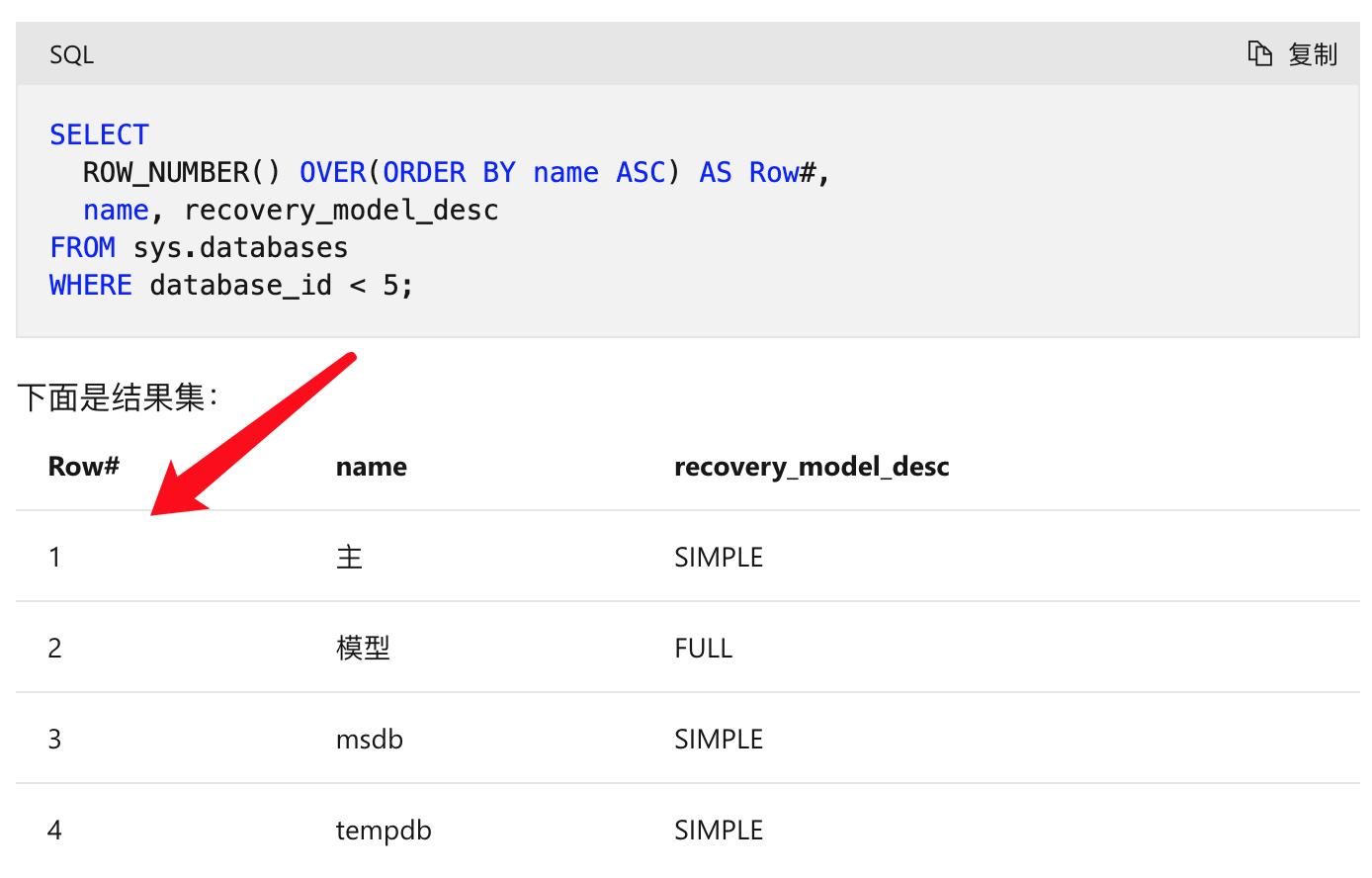
不知道你什么数据库.如果数据库支持 ROW_NUMBER() 函数的话, 倒是很省事的.-- 首先创建测试表CREATE TABLE test_delete( name varchar(10), value INT);go-- 测试数据,其中 张三100 与 王五80 是完全一样的INSERT INTO test_deleteSELECT '张三', 100UNION ALL SELECT '张三', 100UNION ALL SELECT '李四', 80UNION ALL SELECT '王五', 80UNION ALL SELECT '王五', 80UNION ALL SELECT '赵六', 90UNION ALL SELECT '赵六', 70go-- 首先查询一下, ROW_NUMBER 效果是否满足预期SELECT ROW_NUMBER() OVER (PARTITION BY name, value ORDER BY (SELECT 1) ) AS no, name, valueFROM test_deleteno name value----- ---------- ----------- 1 李四 80 1 王五 80 2 王五 80 1 张三 100 2 张三 100 1 赵六 70 1 赵六 90
SQL重复记录查询方法:
1、查找表中多余的重复记录,重复记录是根据单个字段(peopleId)来判断2、删除表中多余的重复记录,重复记录是根据单个字段(peopleId)来判断,只留有rowid最小的记录3、查找表中多余的重复记录(多个字段)