摘要:
mysql读写分离用哪个中间件比较妥?mysql-proxy是官方提供的mysql中间件产品可以实现负载平衡,读写分离,failover等,但其不支持大数据量的分库分表且性能较差。...
摘要:
mysql读写分离用哪个中间件比较妥?mysql-proxy是官方提供的mysql中间件产品可以实现负载平衡,读写分离,failover等,但其不支持大数据量的分库分表且性能较差。... mysql读写分离用哪个中间件比较妥?
mysql-proxy是官方提供的mysql中间件产品可以实现负载平衡,读写分离,failover等,但其不支持大数据量的分库分表且性能较差。
其他mysql开源中间件产品有:Atlas,cobar,tddl。你可以查阅一下相关信息和各自的优缺点。
mysql数据库读取数据?
要先连接服务器 ,再选择数据库mysql_connect("localhost","username","password")
;mysql_select_db("2007"); $sql=mysql_query("select * from news_news order by id desc"); $n=1; while(($row=mysql_fetch_array($sql)) && $n
pandas读取mysql最快方法?
pandas使用read_sql和to_sql方法可以快速读取mysql数据库中的数据,具体步骤如下:
1、首先,创建一个连接,连接到mysql服务器;
2、选择要读取的数据,编写SQL语句;
3、使用pandas中的read_sql()函数,读取数据;
4、将数据转换成DataFrame格式;
5、使用to_csv()方法,将数据保存成csv格式。
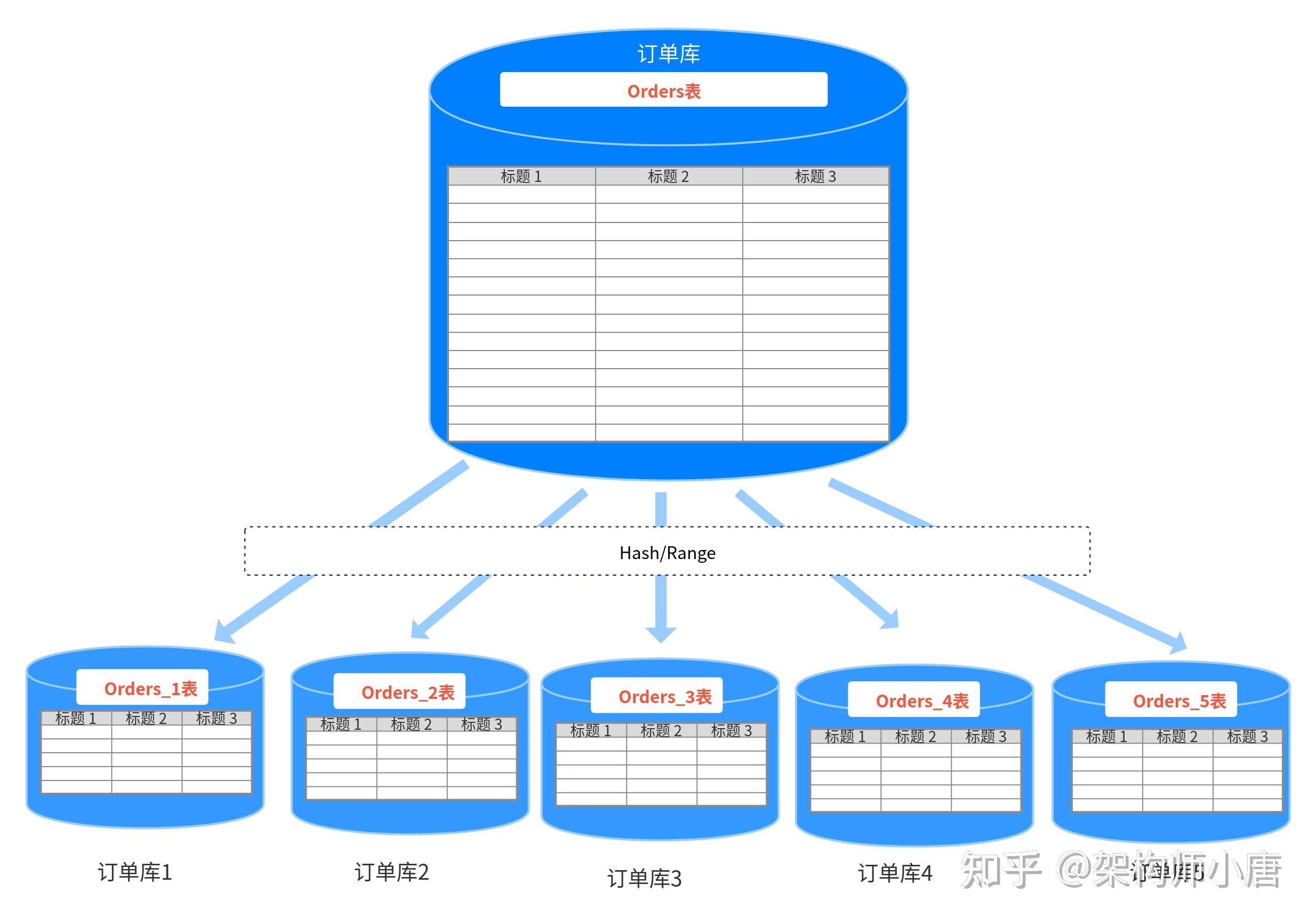
Mysql读写分离原理及主众同步延时如何解决?
我们知道,大型网站为了缓解高并发访问,往往会给网站做负载均衡,但这远远不够。我们还需要对数据库层做优化,因为大量的数据查询单靠一台数据库服务器很难抗得住,这时候我们就需要做读写分离了。
什么是读写分离?
所谓的“读写分离”是指将数据库分为了主库和从库,其中主库用来写入数据,(多个)从库用来读取数据。

读写分离是为了解决什么问题的?
就大多数互联网项目而言,绝大多数都是“读多写少”,所以读操作往往会引发数据库的性能瓶颈,为了解决这个问题,我们就将对数据的读操作和写操作进行分离,避免读写锁带来的冲突,从而提升了数据库的性能。
通俗的说,读写分离是为了解决数据库的读写性能瓶颈的。
MySQL读写分离的原理
MySQL读写分离是基于主从同步的,因为读写分离是将数据读/写操作分流至不同的数据库节点服务器进行操作,这就涉及到了主库和从库的数据同步问题。
MySQL主从同步的原理是:主库将变更记录写入binlog日志(二进程日志),然后从库中有一个IO线程将主库的binlog日志Copy过来写入中继日志中,从库会从中继日志逐行读取binlog日志,然后执行对应的SQL,这样一来从库的数据就和主库的数据保持一致了。

这里需要留意的是,从库同步数据时是串行而非并行操作的!!!即使在主库上的操作是并行的,那在从库上也是串行执行。所以从库的数据会比主库要慢一些,尤其是在高并发场景下延迟更为严重!
MySQL主从同步延时问题如何解决?
上面讲到了,之所以导致MySQL主从同步存在延迟的原因是从库同步数据时是串行而非并行执行的。
要解决主从同步延迟,有几个可行方案供大家参考:
1、我们可以使用并行复制来处理同步。什么是并行复制呢?并行复制指的就是从库开启多个线程并行读取relay log 中的日志;
2、对实时性要求严格的业务场景,写操作后我们强制从主库中读取;
以上就是我的观点,对于这个问题大家是怎么看待的呢?欢迎在下方评论区交流 ~ 我是科技领域创作者,十年互联网从业经验,欢迎关注我了解更多科技知识!
这个问题问得好!
工作中遇到过不少这个问题,由于数据库读者分离或者主从同步都需要一定时间,由于
怎么解决?
代码中规避
写库完成之后返回数据通过缓存处理,适当允许不可重复读!
数据库主从配置优化
仅用从库的binlog同步,logs-slave-updates不记录主从产生日志等方式减小主从同步压力。
提高硬件配置,确保主从数据库在同一个局域网
提高主从数据库物理机配置,包括IO,带宽,CPU等,使用SSD。注意尽量在同一个局域网部署主从服务器。
没有时间细化了,大致上也就这些吧,从代码到架构到硬件,这也是我们考虑问题的常规思路!望采纳!