摘要:
mysql的mha高可用原理?1.主库挂了,但是主库的binlog都被全部从库接收 此时会选中应用binlog最全的一台从库作为新的主库,其他从主只需要重新指定一下主库即可(因为此...
摘要:
mysql的mha高可用原理?1.主库挂了,但是主库的binlog都被全部从库接收 此时会选中应用binlog最全的一台从库作为新的主库,其他从主只需要重新指定一下主库即可(因为此... mysql的mha高可用原理?
1.
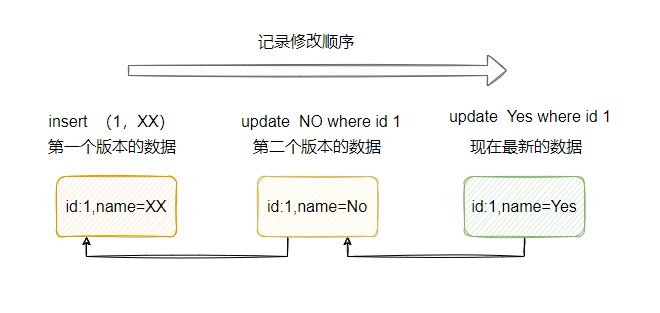
主库挂了,但是主库的binlog都被全部从库接收 此时会选中应用binlog最全的一台从库作为新的主库,其他从主只需要重新指定一下主库即可(因为此时,所有从库都是一致的,所以只需要重新指定一下从库即可)。
2.
主库挂了,所有的binlog都已经被从库接收了,但是,主库上有几条记录还没有sync到binlog中,所以从库也没有接收到这个event,如果此时做切换,会丢失这个event。 此时,如果主库还可以通过ssh访问到,binlog文件可以查看,那么先copy该event到所有的从库上,最后再切换主库。
3.
如果使用半同步复制,可以极大的减少此类风险。 主库挂了,从库上有部分从库没有接收到所有的
如何设计和实现高可用的MySQL?
有关数据库高可用实现,分别以主流的Oracle、Mysql的实现方式来进行阐述。
为了解决数据库的单点故障,提供系统的整体可用性,存在以下两种技术路线:
路线1:基于传统数据库的高可用集群,主要包括共享存储(Share-Storage)、全共享(Share-Everything)和无共享(Share-Nothing)等;
路线2:基于NewSQL数据库的高可用架构,如谷歌的Spanner/F1数据库、阿里的OceanBase分布式数据库。
MySQL主从集群
基于“Share-Nothing架构”的数据库集群,具备数据冗余,能快速实现主备切换,具有更高的可用性。
在保证数据一致性、完整性及高可用性的前提下,采用MySQL半同步复制+MHA复制管理工具的方案。

如上图所示,本方案采用MySQL一主多从的架构方式,主节点提供数据的读写服务,从节点提供数据的只读服务,主从节点间通过MySQL的主从复制机制来单向同步数据。另外,将MHA Manager单独部署到一台服务器,来管理MySQL集群,控制Master节点的故障切换,保证整个集群的高可用。
MHA(Master High Availability)负责MySQL的故障切换和主从提升等功能。在MySQL故障切换过程中,MHA能做到在0~30秒之内自动完成数据库的故障切换操作,并且在进行故障切换的过程中,MHA能在最大程度上保证数据的一致性,以达到真正意义上的高可用。
该软件由两部分组成:MHA Manager(管理节点)和MHA Node(数据节点)。MHA Manager可以单独部署在一台独立的机器上管理多个Master-Slave集群,也可以部署在一台Slave节点上。MHA Node运行在每台MySQL服务器上,MHA Manager会定时探测集群中的Master节点,当Master出现故障时,它可以自动将最新数据的Slave提升为新的Master,然后将所有其他的Slave重新指向新的Master。整个故障转移过程对应用程序完全透明。
2. Oracle RAC集群
基于“Share-Everything架构”的数据库集群,不仅共享存储,还共享缓存。
RAC通过不同的节点使用一个或者多个Oracle实例(Instance)与一个数据库(Database)连接,该数据库存放于多个节点的共享存储(Share Storage)上,通过高速缓存合并技术使得集群中的每个节点可以通过高速集群互联高效的同步其内存高速缓存,从而最大限度地减低磁盘IO,并且自动并行处理及均匀分布负载,当其中一个节点发生故障时可以自动容错和恢复能力来实现节点的故障切换(Failover),从而保证数据库的高可用性。
RAC架构的软、硬件结构:

这个问题问的有点不是太明确,可以分成两个方面回答
1.数据库设计的规范性,起码需要符合数据库设计三范式
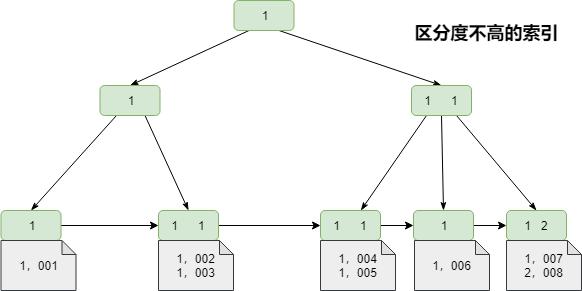
2.数据库高可用性设计方法,就数据量来看,百万级的单表容量,mysql基本上没有什么问题,需要注意的是索引建立需要合理,既不能太多,影响插入性能,也不能太少,影响查询性能,这个需要看实际业务表的情况而定。
3.数据量太大的情况,可以考虑两个方向,
a.先考虑读写分离,用主从库的方式分解读和写的压力
b.分库分表,这一步也有很多中间件可以使用,分库分表也可以分成垂直分和水平分两种情况。