摘要:
mysql中in的数量多如何优化?当在MySQL中使用IN子句时,如果数量非常大,可能会影响查询性能。以下是一些优化建议:使用索引:确保你正在查询的列上有适当的索引。索引可以大大提...
摘要:
mysql中in的数量多如何优化?当在MySQL中使用IN子句时,如果数量非常大,可能会影响查询性能。以下是一些优化建议:使用索引:确保你正在查询的列上有适当的索引。索引可以大大提... mysql中in的数量多如何优化?
当在MySQL中使用IN子句时,如果数量非常大,可能会影响查询性能。以下是一些优化建议:
使用索引:确保你正在查询的列上有适当的索引。索引可以大大提高查询速度,特别是对于大型数据集。
拆分查询:如果IN子句中的值过多,可以考虑将其拆分成多个查询。每个查询将具有更少的条件,这使得数据库更容易优化并提高执行效率。
使用OR逻辑:如果可以使用OR逻辑代替IN子句,可能会得到更好的性能。例如,使用WHERE column1 = 'value1' OR column2 = 'value2'代替WHERE (column1, column2) IN (('value1', 'value2'))。
使用临时表:可以将查询结果存储在一个临时表中,然后在该临时表上进行进一步的查询操作。这样可以避免重复执行相同的查询。
限制结果集:如果可能,可以限制返回的结果集大小,只获取所需的几行数据,而不是返回所有匹配的行。
数据库优化:确保数据库服务器具有良好的硬件配置和参数设置。这包括足够的内存、合适的磁盘速度和正确的操作系统配置。
定期清理数据:如果你的表中包含大量不必要的数据,可以考虑定期进行数据清理,以减少数据量并提高查询性能。
数据库分区:如果你的数据库支持分区,可以将表按照逻辑或物理方式进行分区。这有助于将大型数据集拆分为更小的部分,提高查询性能。
使用其他技术:如果以上方法仍然无法满足性能需求,可以考虑使用其他技术,如使用程序代码进行分页或过滤操作,或者使用专门的搜索引擎来处理复杂的查询需求。
请注意,这些优化建议可能需要根据具体情况进行调整和测试。在实施任何更改之前,建议先备份数据库并进行性能测试以确定最佳方案。
若MySQL中IN操作的数量过多,可以采取以下优化措施:
1. 使用JOIN操作代替IN操作,将子查询转化为连接查询,因为连接查询通常能更高效地处理大量数据。
2. 将IN子查询结果存储到临时表中,并创建合适的索引,可减少查询时间。

图片来源:网络
3. 使用EXISTS替代IN,EXISTS只需找到第一个匹配项后即停止查询,效率更高。
4. 如果IN操作的值是连续的整数,可以考虑使用BETWEEN操作。
5. 如果IN操作的值是离散的,可以将数据存储在临时表中,并使用JOIN操作进行连接查询。
6. 合理优化查询语句,使用合适的索引和查询优化器,避免全表扫描和不必要的排序操作。
mysql in会使用索引吗?
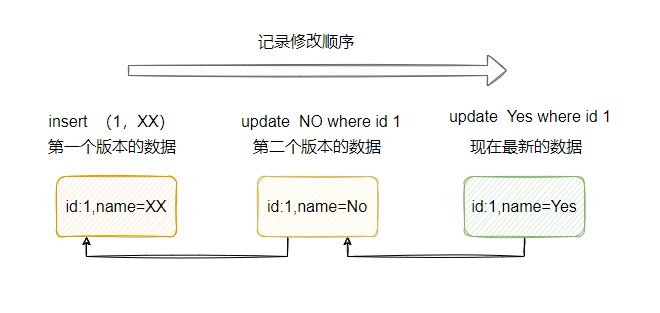
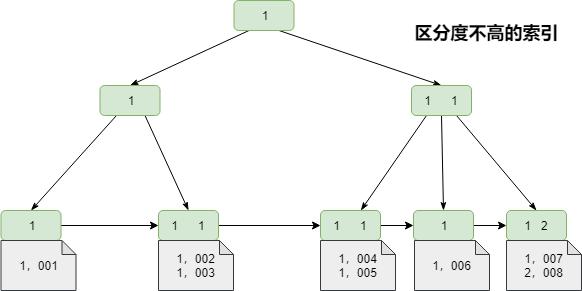
当你source字段唯一性不高,例如你90w数据,里面source字段来来去去就那么十几个值,这种情况下影响结果集巨大,就会全表扫描。这种情况全表扫描还要快于利用索引,只要理解索引的本质不难明白MySQL为何不使用索引。
极端点的情况,90万的数据,source只有0和1两个值,利用索引要先读索引文件,然后二分查找,找到对应数据的数据磁盘指针,再根据读到的指针再读磁盘上对应的数据数据,影响结果集45万。这种情况,和直接全表扫描那个快显而易见。
如果你source字段是一个unique,就会用到索引。
如果你一定要用索引,可以用force index,不过效率不会有改善一般还会更慢就是了。