摘要:
mysql四个索引怎么建立?mysql四个索引建立语句如下:create index 索引名 on table_name(column1,column2);alter table...
摘要:
mysql四个索引怎么建立?mysql四个索引建立语句如下:create index 索引名 on table_name(column1,column2);alter table... mysql四个索引怎么建立?
mysql四个索引建立语句如下:
create index 索引名 on table_name(column1,column2);
alter table table_name add index 索引名(column1,column2);
mysql innodb建立普通索引怎么写?
先从数据结构的角度来答。
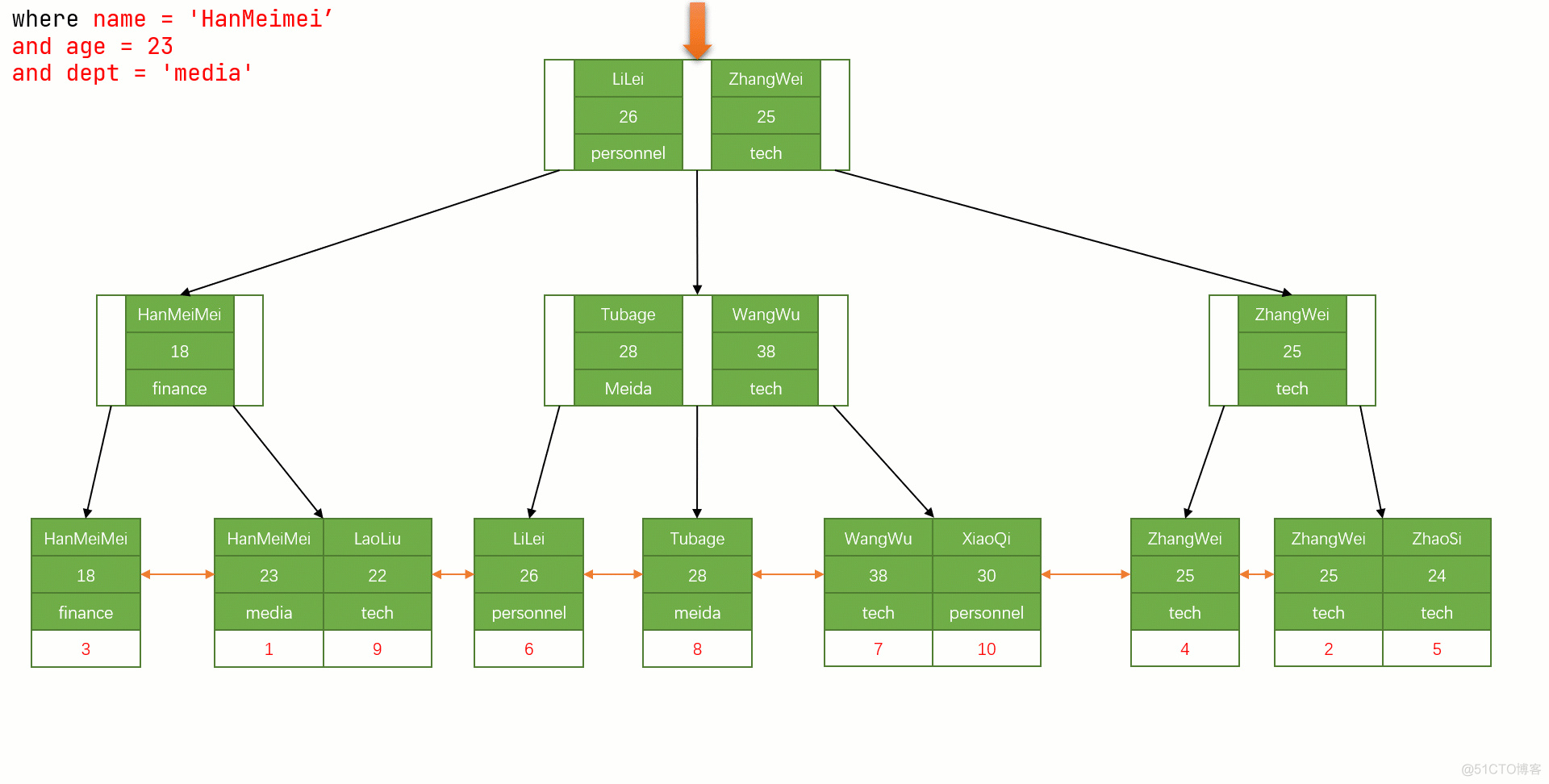
题主应该知道B-树和B+树最重要的一个区别就是B+树只有叶节点存放数据,其余节点用来索引,而B-树是每个索引节点都会有Data域。
这就决定了B+树更适合用来存储外部数据,也就是所谓的磁盘数据。
从Mysql(Inoodb)的角度来看,B+树是用来充当索引的,一般来说索引非常大,尤其是关系性数据库这种数据量大的索引能达到亿级别,所以为了减少内存的占用,索引也会被存储在磁盘上。
那么Mysql如何衡量查询效率呢?磁盘IO次数,B-树(B类树)的特定就是每层节点数目非常多,层数很少,目的就是为了就少磁盘IO次数,当查询数据的时候,最好的情况就是很快找到目标索引,然后读取数据,使用B+树就能很好的完成这个目的,但是B-树的每个节点都有data域(指针),这无疑增大了节点大小,说白了增加了磁盘IO次数(磁盘IO一次读出的数据量大小是固定的,单个数据变大,每次读出的就少,IO次数增多,一次IO多耗时啊!),而B+树除了叶子节点其它节点并不存储数据,节点小,磁盘IO次数就少。这是优点之一。
另一个优点是什么,B+树所有的Data域在叶子节点,一般来说都会进行一个优化,就是将所有的叶子节点用指针串起来。这样遍历叶子节点就能获得全部数据,这样就能进行区间访问啦。
至于MongoDB为什么使用B-树而不是B+树,可以从它的设计角度来考虑,它并不是传统的关系性数据库,而是以Json格式作为存储的nosql,目的就是高性能,高可用,易扩展。首先它摆脱了关系模型,上面所述的优点2需求就没那么强烈了,其次Mysql由于使用B+树,数据都在叶节点上,每次查询都需要访问到叶节点,而MongoDB使用B-树,所有节点都有Data域,只要找到指定索引就可以进行访问,无疑单次查询平均快于Mysql(但侧面来看Mysql至少平均查询耗时差不多)。
总体来说,Mysql选用B+树和MongoDB选用B-树还是以自己的需求来选择的。
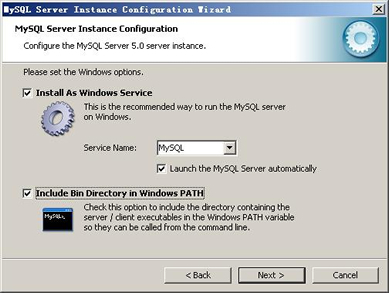
mysql几千w创建索引多长时间?
32核心,30多G 内存,一千万的条目在时间上建立非聚集索引,用了 7 分钟。
一亿的话,我这估计要大于70分钟。聚集索引时间更长。这个需要索引排序,建立分支索引复合B树。一般海量数据不如新建立表,建立好索引,然后逐批导入数据。我要对mysql中的数据建立倒排索引应该怎么?
MySQL长期以来对索引的建立只允许正向asc存储,就算建立了desc,也是忽略掉。
比如对于以下的查询,无法发挥索引的最佳性能。
查询一:
select * from tb1 where f1 = ... order by id desc;
查询二:
2. select * from tb1 where f1 = ... order by f1 asc , f2 desc;
那对于上面的查询,尤其是数据量和并发到一定峰值的时候,则对OS的资源消耗非常大。一般这样的SQL在查询计划里面会出现using filesort等状态。
比如针对下面的表t1,针对字段rank1有两个索引,一个是正序的,一个是反序的。不过在MySQL 8.0 之前的版本都是按照正序来存储。
按照rank1 正向排序的执行计划,
按照rank1 反向排序的执行计划,
从执行计划来看,反向比正向除了extra里多了Using temporary; Using filesort这两个,其他的一模一样。这两个就代表中间用到了临时表和排序,一般来说,凡是执行计划里用到了这两个的,性能几乎都不咋地。除非我这个临时表不太大,而用于排序的buffer也足够大,那性能也不至于太差。那这两个选项到底对性能有多大影响呢?