摘要:
mysql分库分表如何解决数据倾斜问题?在MySQL的分库分表架构中,为了解决数据倾斜问题,可以采取以下几种方法:1. 哈希分片(Hash Sharding):使用哈希函数对分片键...
摘要:
mysql分库分表如何解决数据倾斜问题?在MySQL的分库分表架构中,为了解决数据倾斜问题,可以采取以下几种方法:1. 哈希分片(Hash Sharding):使用哈希函数对分片键... mysql分库分表如何解决数据倾斜问题?
在MySQL的分库分表架构中,为了解决数据倾斜问题,可以采取以下几种方法:
1. 哈希分片(Hash Sharding):使用哈希函数对分片键(如用户ID、订单ID)进行哈希计算,将数据分散到不同的库和表中。通过合理选择哈希函数,可以使数据在分片中均匀分布,从而减少数据倾斜。
2. 范围分片(Range Sharding):根据数据的范围将其分片到不同的库和表中。可以根据业务需求选择合适的范围,如按时间范围分片,将不同时间段的数据存储在不同的库或表中。
3. 垂直拆分(Vertical Partitioning):将表按照列的关系和使用频率进行拆分,将不同的列分到不同的表中。这样可以减少单个表的数据量,降低数据倾斜的可能性。
4. 水平拆分(Horizontal Partitioning):将表按照行进行拆分,将不同的行分散到不同的表中。可以根据分片键或其他关键业务字段进行拆分,确保数据在不同分片中均匀分布。
mysql分库分表解决数据倾斜问题
mysql是一种避免避免数据倾斜的手段
允许在map阶段进行join操作,mysql把小表全部读入内存中,在map阶段直接拿另外一个表的数据和内存中表数据做匹配,由于在map是进行了join操作,省去了reduce运行的效率也会高很多
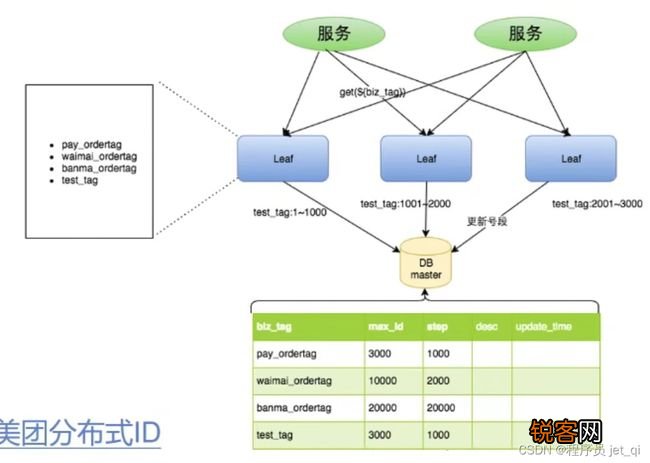
图片来源:网络
在《hive:join遇到问题》有具体操作
在对多个表join连接操作时,将小表放在join的左边,大表放在Jion的右边,
在执行这样的join连接时小表中的数据会被缓存到内存当中,这样可以有效减少发生内存溢出错误的几率
2. 设置参数
hive.map.aggr = true
hive.groupby.skewindata=true 还有其他参数
3.SQL语言调节
比如: group by维度过小时:采用sum() group by的方式来替换count(distinct)完成计算
4.StreamTable
将在reducer中进行join操作时的小table放入内存,而大table通过stream方式读取
Mysql-InnoDB分表真的有意义吗?
分表可以从很多方面提升性能,需要正确的理解这种方法提升性能的原理。
题主举的例子,对数据库的原理了解太少了。
Innodb的行级锁是通过对索引项加锁来实现的,分表但对数据文件大小有影响,他们对应的索引大小也不同,更小的索引,会有更高的性能,在加锁时自然性能会更高。
数据库查询基本都围绕索引做优化,如果某个高频业务出现了不使用索引,直接全表扫描,那是不可接受的。分表提高查询性能的原理在于两点:缩小索引大小和数据文件大小。
另外,对于分库分表,最重要的是分表维度,以哪些数据项作为分表的依据,对性能的影响至关重要,不恰当的分表方法,不但不会提升性能,甚至会降低性能。