摘要:
对MySQL慢查询日志进行分析的基本教程?开启慢查询日志mysql>setglobalslow_query_log=1;定义时间SQL查询的超时时间mysql&...
摘要:
对MySQL慢查询日志进行分析的基本教程?开启慢查询日志mysql>setglobalslow_query_log=1;定义时间SQL查询的超时时间mysql&... 对MySQL慢查询日志进行分析的基本教程?
开启慢查询日志
mysql>setglobalslow_query_log=1;
定义时间SQL查询的超时时间
mysql>setgloballong_query_time=0.005;
查看慢查询日志的保存路径
mysql>showglobalvariableslike'slow_query_log_file';
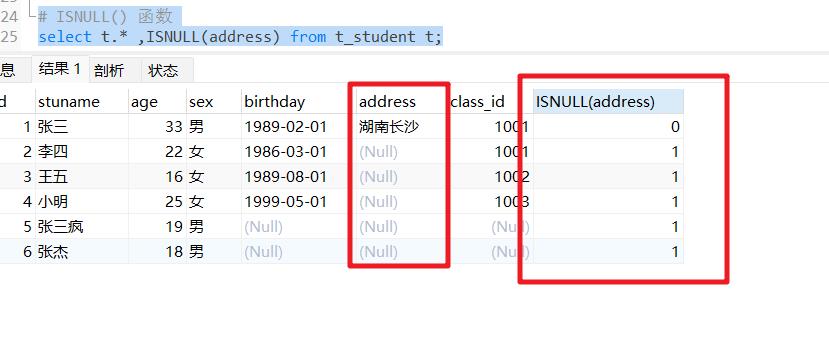
查看慢查询

图片来源:网络
cat/var/log/mysql/slow.log
hive为什么查询速度比mysql慢?
Hive相对于MySQL查询速度慢的主要原因包括:
1. 数据存储和处理方式:Hive是基于Hadoop分布式文件系统(HDFS)的数据仓库,而MySQL是关系型数据库管理系统(RDBMS)。Hive将数据存储在HDFS中,需要通过MapReduce来处理和查询数据,而MySQL使用基于索引的查询方式,可以更快地检索数据。
2. 数据格式和压缩:Hive默认使用文本格式存储数据,而MySQL使用二进制格式。在查询数据时,文本格式需要进行解析,增加了查询的开销。此外,Hive也支持数据压缩,但压缩和解压缩过程会带来计算开销。
3. 查询优化:Hive是一个批处理框架,适用于大规模数据处理和分析。它执行查询时需要进行多个阶段的MapReduce任务,包括数据读取、数据转换和聚合等,每个阶段都需要进行磁盘IO和网络传输,导致查询速度相对较慢。而MySQL使用了更多的查询优化技术,如索引、查询缓存和预编译等,可以更快地执行查询操作。
4. 数据规模和并行性:由于Hive适用于处理大规模数据集,它通常在大型集群上运行,可以在多个计算节点上并行处理数据。但对于小规模数据集和单个计算节点上的查询,Hive的查询性能可能会受到限制。
总的来说,Hive的设计目标是为了处理大规模数据集的分布式计算,而MySQL则更适用于小规模数据集和在线事务处理。因此,在查询速度方面,MySQL通常会比Hive更快。
mysqlinnodbcount(distinct)很慢,怎么优化?
1. 把你的day字段类型改为long型,在页面显示的时候在格式化成自己需要的样式;
2. 在day字段上建立索引;
3. 把ip_4表类型有InnoDB改为MyISAM,如果不需要事物支持的话,建议不要使用InnoDB。
mysql中数据量大时超30万,加上order by速度就变慢很多,一般需要0.8秒左右,不加只需要0.01几秒?
那肯定的
ORDERY BY是要对某个字段进行排序的,有人喜欢加索引解决,但是若是对于一个频繁有写操作的表来说,一个索引还好说,要是有多个索引,数据表的大小增加会相当惊人
另上,建议使用InnoDB引挚,有人说这样速度会快很多
对于大数据级的数据库来说,最关键的一步还是要优化好你的SQL,还有就是使用非常规的作法,供参考
1,以牺牲空间换取速度,就是说看能不能进行一些适当的缓存
2,以牺牲速度换取空间,这对于小空间容量的主机可以采用
为什么mysql中delete比insert要慢?
MySQL的默认的调度策略可用总结如下:写入操作优先于读取操作。
对某张数据表的写入操作某一时刻只能发生一次,写入请求按照它们到达的次序来处理。对某张数据表的多个读取操作可以同时地进行。那么 delete相当于先查找再移除,因此必然慢于insert插入~