摘要:
mysql语句中in的字段过多怎么优化?当使用多个字段进行IN子查询时,可以考虑将这些字段的值放入临时表中,并通过JOIN来优化查询性能。首先创建临时表,然后将需要过滤的值插入临时...
摘要:
mysql语句中in的字段过多怎么优化?当使用多个字段进行IN子查询时,可以考虑将这些字段的值放入临时表中,并通过JOIN来优化查询性能。首先创建临时表,然后将需要过滤的值插入临时... mysql语句中in的字段过多怎么优化?
当使用多个字段进行IN子查询时,可以考虑将这些字段的值放入临时表中,并通过JOIN来优化查询性能。
首先创建临时表,然后将需要过滤的值插入临时表中,最后通过JOIN把临时表和原表连接起来进行查询。这样可以避免过多字段在IN子查询中造成性能下降的问题。同时,也可以考虑对需要过滤的字段进行索引优化,提高查询效率。
mysql使用groupby和order导致速度很慢,请问该怎样优化?
1、使用用索引 注意有些情况下不能够使用索引来提高Order By语句的查询性能。
这里需要注意的是,并不是任何情况下都能够通过使用索引来提高Order Byz子句的查询效率。
如对不同的关键字使用这个语句、混合使用ASC模式和DESC模式、用于查询条件的
mysql数据表规模九千万左右,怎么优化查询?
我的天啦,一个表九千万也是了不得了!
我上家公司明确规定,一张表不能超过5000万,因为查询效率会有更大的降低!
无论如何,看下如何优化数据查询吧!
①,单库单表:
1,加索引,一个好的索引能用空间换取查询时间的大为降低!
2,使用存储过程:减少sql编译的时间!
3,优化sql:包括联合查询的指向,where,order语句使用索引字段,减少使用多表联合查询,不要使用select *等等!
4,参数配置:扩大内存,调节线程池参数等等!
5,开启缓存:开启二级缓存,三级缓存,提升查询效率!

②,单库多表:
使用水平拆分(比如按月份),将表分为12张表,然后在代码端按照月份访问相应月份的表!
使用垂直拆分:很多字段只是作为保存记录用,(像一些约定,备注啥的字段往往很大),可以将查询中常常用到的字段放在常用的一张表中做查询,另一些字段放另一张表中存储,通过某个唯一索引字段联系起来,可以保证查询效率大为提升(因为磁盘IO减少)!

③,多库多表:
①,主从读写分离:表中数据虽然还是一致,但是由于多个从库读,主库写数据,大大减少共享锁的性能开销!
②,分库分表:指定一个字段作为,分库字段,利用hash值或者其它策略,分布在不同的库里面,在按照相应分布策略(比如上面的水平拆分或者垂直拆分),分散到不同的表里!

比如我们现在的数据库设计为8库1024表,你的将近一亿的数据在我们的单张表里面只有不到10W!
虽然理论上,一张表的大小不做任何限制,但是基于查询效率,索引性能等,不宜超出5000万数据!
关于多线程,分布式,微服务,数据库,缓存的更多干货,会继续分享,敬请关注。。
实践出真知。根据成本顺序依次是:
第一:加索引优化sql。尽量避免全盘扫描,另单表索引也不是越多越好。
第二:加缓存。使用redis,memcached,但注意缓存同步更新、设置失效等问题。
第三:主从复制,读写分离。适合读多写少的场景,同步会有延迟。
第四:垂直拆分。可以选用适当的中间件Mycat等
第五:水平切分。选择合理的sharding key,改动表结构,将大数据字段拆分出去,对经常查询的字段做一定的冗余,同时做好数据同步。
当然还有优化数据库连接配置,根据业务选用不同的数据库引擎等等。
我是一名架构师,欢迎关注,给技术加点料
我不清楚答题的大部分人是否有真正实践过,特别是用mysql实践过。大部分说是加索引、调整参数不是说不正确,有效果,但是不能很好的解决问题。说说个人想法:
部分答主的方案的确不敢苟同,纠正如下:
1、select count(*) 和 select count(主键) 在现阶段的mysql 没有太大区别,新版mysql这个对性能影响可以忽略。
2、强烈反对使用存储过程,后面介绍了使用分表分库的方案,就更不要用存储过程了。
3、单表行数和表数量,需要找到平衡点。表太多,性能也会下降。
我的回答:
1、单表9000w数据,mysql存储不了,想办法分表分库。500w数据的时候,你就该有这个想法了。只加索引解决不了问题,9000w的单表数据,很难平衡查找和插入性能,索引稍微多了插入性能也很低。
2、不要再说select count了,放弃汇总查询的想法,根本查不了。
3、数据最终以mysql作为主要存储,考虑最终查询的数据源放在非关系的数据存储上,mongo,es都可以考虑下。
4、业务场景都是需要实时查询9000w数据吗?非实时数据,可以考虑hadoop系大数据方案。
5、最后说下,mysql 和oracle,sql server不一样,不一样。
读写分离,分库分表,热数据放内存。
读写分离:减少写库所带来的行锁甚至表锁对查询的影响,提升查询效率,同时还可以保证高可用。
在设计系统之初就设计好垂直分库和垂直分表,比如垂直分表:在一张大表中,一些热数据的字段放在一起,一些不常用的而且占用空间比较大的字段放在另外一张表,这样子做的好处是提升了查询速度,因为mysql是以页存储数据的,一页之中存放的数据越多,查询效率会更高。
另外再配合redis mongodb这些缓存数据库,热数据放进去,查询效率会进一步得到提升。
如果上面的方案还无法解决查询缓慢的问题,可能是因为我们的数据量非常大,而且持续快速增长。我们还可以进行水平分库分表,例如把一张1亿数据量的大表,水平拆分成10张相同的大表,再水平拆分到10个不同的数据库中。。。
觉得可以的点个赞
是一张表九千万了吗?
建议:
第一、表读居多还是写?读的话数据库引擎用myisam ,写的话InnoDB 而不是MyISAM,因为MyISAM有太多锁。
第二、升级到MySQL 5.5 ,确保使用buffering功能。
第三,索引确保使用正确,且都在内存中,移除没有必要的索引。
第四、写场景多吗? 设置innodb_buffer_pool_size足够大来确保更快的写操作。
第五、按业务id取模,分表。
最后,花钱加机器内存和用ssd磁盘吧。
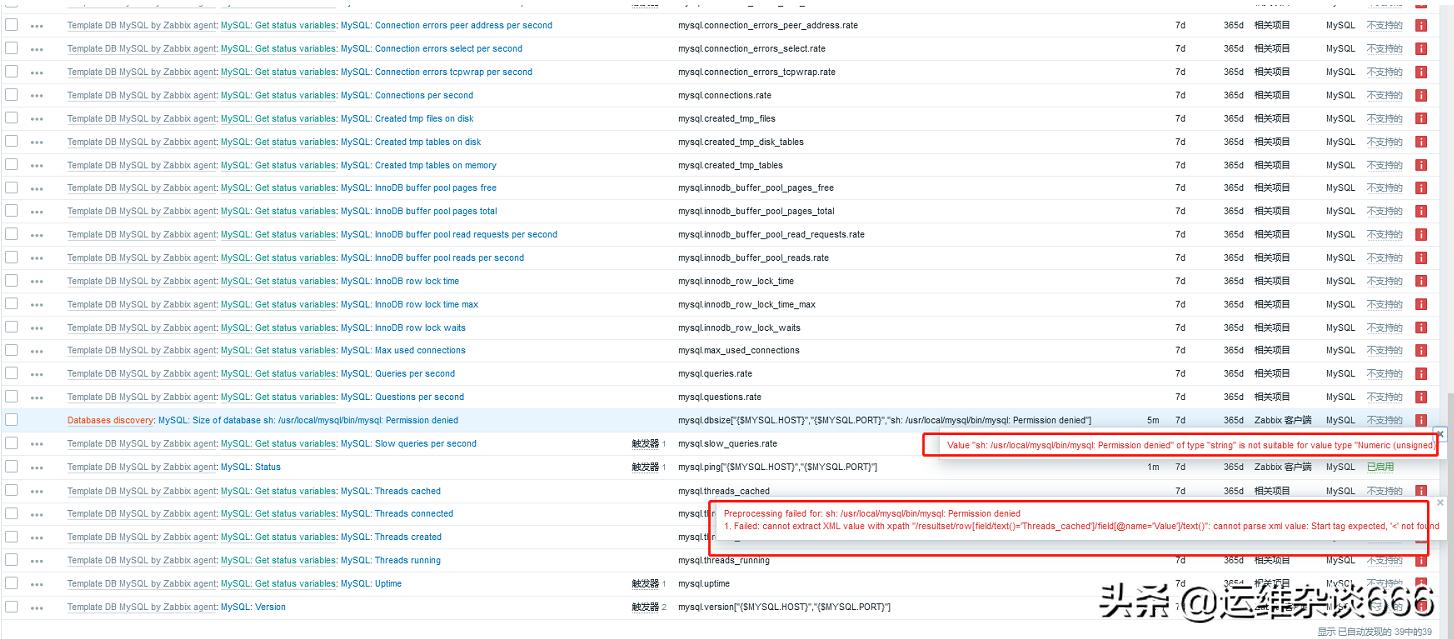
mysql如何定期分析检查与优化表?
1. 对表进行优化 ( 优化表主要作用是消除删除或者更新造成的空间浪费)
2. 对表进行分析(分析关键字的分布, 分析并存储MyISAM和BDB表中键的分布)
3. 对表进行检查(检查表的错误,并且为MyISAM更新键的统计内容)
4. 对表进行修复(修复被破坏的MyISAM表)
分析表
ANALYZE TABLE 表名1 [,表名2…] ;
ANALYZE TABLE分析表的过程中,数据库系统会对表加一个只读锁。在分析期间,只能读取表中的记录,不能更新和插入记录。ANALYZE TABLE语句能够分析InnoDB和MyISAM类型的表。
对表的定期分析可以改善性能,且应该成为常规维护工作的一部分。因为通过更新表的索引信息对表进行分析,可改善数据库性能。
检查表
MySQL中使用CHECK TABLE语句来检查表。CHECK TABLE语句能够检查InnoDB和MyISAM类型的表是否存在错误。还可以检查视图是否存在错误.
check table 表名
优化表
随着MySQL的使用,包括BLOB和VARCHAR字节的表将变得比较繁冗,因为这些字段长度不同,对记录进行插入、更新或删除时,会占有不同大小的空间,记录就会变成碎片,且留下空闲的空间。像具有碎片的磁盘,会降低性能,需要整理,因此要优化。 (个人理解:当删除数据之后,原来的索引文件位置会空出来。等待新文件的插入,optimize命令就是整理索引文件)
针对MyISAM表,直接使用如下命令进行优化
optimize table table1[,table2][,table3]
myisam
innodb
Table does not support optimize, doing recreate + analyze instead。因为Innodb结构下删除了大量的行,此时索引会重组并且会释放相应的空间因此不必优化。
show table status like ‘表名’;
如何使用phpMyadmin优化MySQL数据库?
phpMyadmin仅仅是一个数据库管理工具,与Mysql数据库优化应该是很松耦合的。下面简单谈谈MySql数据库的几个优化点:
1、优化SQL语句
比如尽量少用"select * from ...",需要什么字段返回什么字段,可以有效节省网络IO,缩短查询时间,还可以增加Mysql服务器的吞吐量。
再比如需要select最近一个月的数据,数据量比较大;拆成10次请求,每次请求select三天的,效果可能会好很多。
再比如使用join做表连接的时候,尽量用小表驱动大表,简单来说就是left join,左表是驱动表;right join 右表是驱动表;inner join mysql会自动做优化
学会使用EXPLAIN关键字辅助优化

优化SQL语句是数据库优化的首选;
2、优化表结构
比如字段类型,可以用数字的字段,尽量不要用Text,比如订单Id一般都是数据。
小字段能满足要求的,尽量不要用大字段
根据业务场景,在合适的字段上添加索引,提高搜索速度
适当的做字段冗余和缩减
3、表的拆分
数据库表一般分为纵向拆分和横向拆分,纵向拆分就是将一个表按照列拆分成多个表,通过外键连接。横向拆分就是按照某个字段(比如:时间)做拆分。

数据库拆分
对于数据量太大,或者QPS很大的场景,就需要分库处理。比如设置主库和从库,主库用于写数据,从库用于读数据

以上优化手段,部分可以借助phpMyadmin实现。
更详细的优化手段欢迎点击我的头像,关注我,查看我之前写的Mysql系列文章。
大家觉得这个回答怎么样呢??