摘要:
如何优化Mysql千万级快速分页?两步。1,垂直分表。拆表,按你的各个应用场景,如微信登录、qq登录,每个应用场景一张表,这张表的字段比原表少,仅仅将该场景用到的字段存进去。2,水...
摘要:
如何优化Mysql千万级快速分页?两步。1,垂直分表。拆表,按你的各个应用场景,如微信登录、qq登录,每个应用场景一张表,这张表的字段比原表少,仅仅将该场景用到的字段存进去。2,水... 如何优化Mysql千万级快速分页?
两步。
1,垂直分表。拆表,按你的各个应用场景,如微信登录、qq登录,每个应用场景一张表,这张表的字段比原表少,仅仅将该场景用到的字段存进去。
2,水平分表。经过第一部后,将每个子表进行水平拆分,。具体方法,比如手机号登录场景的子表,可按手机号末尾一位取模,再分为10个子表,每个子表数据量百万级,mysql性能差不多可以忍受。对了,别忘建个索引。
总结一下,要达到的目的无非两个:瘦表,单表数据量级不要超过百万级
mysql分页技术中用到的关键字?
mysql数据库分页用limit关键字,它后面跟两个参数:startIndex和pageSize。如:请求第2页,每页10条数据,departmentId代表部门编码,以科研部的员工为例,假设其部门编码为1001Java code:
int cpage = 2;int pageSize = 10;int startIndex = (cpage-1)*pageSize;String sql = "select * from deployees from departmentid='1001' limit "+startIndex+","+pageSize;
为什么MySQL在数据库较大的时候分页查询很慢,如何优化?

使用合理的分页方式以提高分页的效率
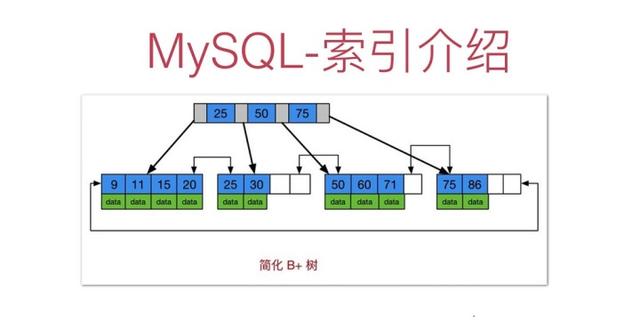
正如楼主所说,分页查询在我们的实际应用中非常普遍,也是最容易出问题的查询场景。比如对于下面简单的语句,一般想到的办法是在name,age,register_time字段上创建复合索引。这样条件排序都能有效的利用到索引,性能迅速提升。

如上例子,当 LIMIT 子句变成 “LIMIT 100000, 50” 时,此时我们会发现,只取50条语句为何会变慢?
原因很简单,MySQL并不知道第 100000条记录从什么地方开始,即使有索引也需要从头计算一次,因此会感觉非常的慢。
通常,我们在做分页查询时,是可以获取上一页中的某个数据标志来缩小查询范围的,比如时间,可以将上一页的最大值时间作为查询条件的一部分,SQL可以优化为这样:

若对你有所帮助,欢迎点赞、关注支持哦。
题主给的这个sql其实想要的数据也就20条吧(你那个300020应该是打错了,不可能是实际业务一页显示30多万条记录),单纯查三十多万数据其实很快,为什么分页后就很慢?
变慢的原因,一方面是select *,另一方面是数据量较大,还有一个是带有排序操作。本质是分页查询时,会先查询出limit + offset条记录,然后截取后面的offset记录。

Mysql数据库作为一款比较主流的开源关系型数据库,市场上我觉得貌似开发者没有一个没用过吧。
影响MySQL查询性能的因素有很多,比如sql,表结构设计,磁盘io,网卡io,高并发,数据库相关参数配置,还有服务器硬等。
这里面涉及最多也是面试中最常问的就是有关sql的优化。
因为很多性能上的问题来自sql的比较多,mysql数据库在数据量级达到百万以上性能是逐渐下降的。
关于sql优化又有很多优化的方向和手段。比如对表结构的字段类型,默认值,索引等最基础的做一些优化,然后编写的sql最好要能完全命中索引。
当然并不是说建索引就一定命中,不走索引就一定慢。这取决于mysql的执行计划。
还有建索引也并不是越多越好,单表索引最好不要超过6个,毕竟索引也占空间,数据更新的同时,还牵扯到索引文件的维护。
OK说了这么多,到底该怎么对这个分页又排序做优化呢?
我的做法就是合理利用主键索引来处理
select a.* from table a inner join (select id from table
limit 300000,20)
b on a.id=b.id;
然后排序最好放到代码层面上去。
希望我的回答能帮到你