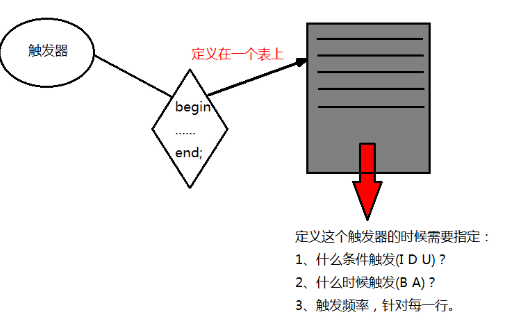
摘要:
Mysql统计如何用索引?Mysql可以使用索引来提高查询的性能和效率。下面是一些关于如何使用索引进行统计的方法:1. 创建适当的索引:在Mysql中,可以使用CREATE IND...
摘要:
Mysql统计如何用索引?Mysql可以使用索引来提高查询的性能和效率。下面是一些关于如何使用索引进行统计的方法:1. 创建适当的索引:在Mysql中,可以使用CREATE IND... Mysql统计如何用索引?
Mysql可以使用索引来提高查询的性能和效率。下面是一些关于如何使用索引进行统计的方法:
1. 创建适当的索引:在Mysql中,可以使用CREATE INDEX语句来创建索引。要选择正确的列或列组合进行索引,以便支持统计查询。
例如,如果要统计表中某个字段的唯一值的数量,可以在该字段上创建一个唯一索引。
2. 使用覆盖索引:覆盖索引是一种特殊类型的索引,其中包含了查询所需的所有列数据。当进行统计查询时,如果可以使用覆盖索引,就可以避免访问主表数据,从而提高查询性能。
3. 避免索引失效:在进行统计查询时,应该尽量避免索引失效。索引失效会导致Mysql不使用索引而进行全表扫描,影响查询性能。
避免索引失效的方法包括:避免在索引列上使用函数、避免在索引列上使用NOT操作符、避免在索引列上使用范围查询(如BETWEEN、>、<等)等。
4. 优化查询语句:优化查询语句可以进一步提高统计查询的性能。例如,可以使用JOIN语句代替子查询、合理使用GROUP BY和ORDER BY语句、使用LIMIT限制返回的记录数量等。
5. 定期更新统计信息:Mysql中的统计信息用于查询优化器进行查询计划的选择。如果统计信息过时,可能导致查询优化器选择了不合适的查询计划,影响查询性能。
因此,定期更新统计信息是提高统计查询性能的一种重要方法。可以使用ANALYZE TABLE语句来更新表的统计信息。
总之,使用合适的索引、避免索引失效、优化查询语句和定期更新统计信息是提高Mysql统计查询性能的关键。
mysql中这条sql语句复合索引怎么建?
建一个单独索引(sortid)。
现在的查询速度都比较慢,字段类型分别为:
sortid=varchar(32),
islock=tinyint(1),
attid=tinyint(2),
author=smallint(4),
topid=tinyint(1)
mysql创建索引的时候支持字段的desc排序方式吗?
MySql创建索引时支持ASC或DESC排序。
下面举例 创建表时同时创建索引降序排序(sname 字段上普通索引降序) create table tbl1 ( id int unique, sname varchar(50), index tbl1_index_sname(sname desc) ); 在已有的表创建索引语法 create [unique|fulltext|spatial] index 索引名 on 表名(字段名 [长度] [asc|desc]);如何构建高性能MySQL索引?
谢邀~
之前写过一篇关于针对开发人员数据库优化的文章,索引也是其中之一,那么今天就针对Mysql索引讲几点。
索引的类型及什么时候建立索引
说到MySQL的索引,大多数时候都是指B-Tree索引,M ySQL大部分引擎都是支持B-Tree索引的。B-Tree索引适用于全键值、范围、前缀的查找;
主键、外键必须有索引,当然很多系统都是逻辑外键(或需要经常和其他表关联),也需要建立索引;经常出现在where、order by、group by中的字段;尽量把索引建立到小字段上;对于文本字段或者很长字段,不要建索引;复合索引,文章第二部分再说明;
哈希索引,是基于哈希表,精确匹配索引所有列的查询才有效;只有Memory引擎支持。
全文索引、聚簇索引、聚簇索引等等,就不详细说了,因为...我也不太会,下面还是主要说B-Tree索引(后来说的索引,都是指B-Tree)。

联合索引的限制
很多同学都喜欢给多个字段建立联合索引,那么建立联合索引需要注意些什么呢:
索引的最左原则,如果不是按索引的最左列查找,那么将无法使用索引。最左原则:如果创建了一个联合索引(name,age,gender),相当于创建了三个索引(name)、(name,age)、(name,age,gender)。
联合索引,左边的列有范围查找,那么右边的列无法使用索引。比如index(age,gender),where age > 20 and gender = 'M';这时候就会有问题。解决办法也很简单,两个字段分别建立索引。

索引的一些小技巧
- 前导模糊查询,会导致索引失效:where name like '%三丰';
- 数据区分度不大,不建议使用索引:where gender = 'M';性别只有男、女、未知三种;
- 等号左边有函数,会索引失效:where LENGTH(col1) = 10;
- 隐式转换的问题:where col2 = '100',col2列是数字,等号左右类型不一致,col2会隐式转换成字符串;
- 尽量不好使用负向查询,例如:!=、not in、not exists;
- 索引不是越多越好。

我将持续分享Java开发、架构设计、程序员职业发展等方面的见解,希望能得到你的关注。