摘要:
mysql读写分离如何保证数据同步?mysql读写分离后,可以采用mysql集群方案中的主备模式保证数据同步。首先将之前两个数据库实例按主备模式部署好。其次按主写备读的方式进行读写...
摘要:
mysql读写分离如何保证数据同步?mysql读写分离后,可以采用mysql集群方案中的主备模式保证数据同步。首先将之前两个数据库实例按主备模式部署好。其次按主写备读的方式进行读写... mysql读写分离如何保证数据同步?
mysql读写分离后,可以采用mysql集群方案中的主备模式保证数据同步。
首先将之前两个数据库实例按主备模式部署好。
其次按主写备读的方式进行读写分离配置。
最后设置主备同步方式,按binlog文件同步数据,并设置好同步数据的频率。
完成上述处理后,即可保证在读写分离的情况下完成数据同步。
mysql只从同步会锁吗?
在MySQL中,同步会导致锁定,因为同步需要在主数据库上执行写操作,这可能会导致锁定表或行。当同步完成并且从服务器已经从主服务器复制了所有更改时,锁定将被释放。为了避免长时间锁定,可以考虑使用基于GTID的异步复制,这可以减少锁定的时间并提高性能。
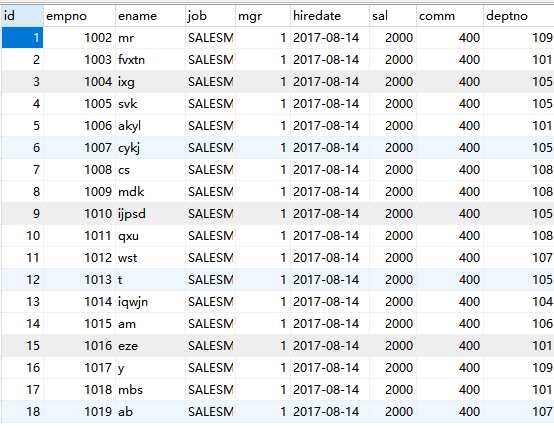
mysql将一个表的数据同步到另一个表?
1.如果2张表的字段一致,并且希望插入全部数据,可以用这种方法:
INSERT INTO 目标表 SELECT * FROM 来源表;
2.如果只希望导入指定字段,可以用这种方法:
INSERT INTO 目标表 (字段1, 字段2, ...) SELECT 字段1, 字段2, ... FROM 来源表;(这里的话字段必须保持一致)
3.如果您需要只导入目标表中不存在的记录,可以使用这种方法:
INSERT INTO 目标表
(字段1, 字段2, ...)
SELECT 字段1, 字段2, ...
FROM 来源表
WHERE not exists (select * from 目标表
where 目标表.比较字段 = 来源表.比较字段);
mysql如何实现两个数据库数据结构实时同步?
mysql怎么实时同步两个数据库实现两个Mysql数据库之间同步同步原理:MySQL 为了实现replication 必须打开bin-log 项,也是打开二进制的MySQL 日志记录选项。
MySQL 的bin log 二进制日志,可以记录所有影响到数据库表中存储记录内容的sql 操作,如insert / update / delete 操作,而不记录select 这样的操作。
因此,我们可以通过二进制日志把某一时间段内丢失的数据可以恢复到数据库中(如果二进制日志中记录的日志项,包涵数据库表中所有数据,那么, 就可以恢复本地数据库的全部数据了)。
而这个二进制日志,如果用作远程数据库恢复,那就是replication 了。这就是使用replication 而不用sync 的原因。这也是为什么要设置bin-log = 这个选项的原因。
Mysql读写分离原理及主众同步延时如何解决?
我们知道,大型网站为了缓解高并发访问,往往会给网站做负载均衡,但这远远不够。我们还需要对数据库层做优化,因为大量的数据查询单靠一台数据库服务器很难抗得住,这时候我们就需要做读写分离了。
什么是读写分离?
所谓的“读写分离”是指将数据库分为了主库和从库,其中主库用来写入数据,(多个)从库用来读取数据。

读写分离是为了解决什么问题的?
就大多数互联网项目而言,绝大多数都是“读多写少”,所以读操作往往会引发数据库的性能瓶颈,为了解决这个问题,我们就将对数据的读操作和写操作进行分离,避免读写锁带来的冲突,从而提升了数据库的性能。
通俗的说,读写分离是为了解决数据库的读写性能瓶颈的。
MySQL读写分离的原理
MySQL读写分离是基于主从同步的,因为读写分离是将数据读/写操作分流至不同的数据库节点服务器进行操作,这就涉及到了主库和从库的数据同步问题。
MySQL主从同步的原理是:主库将变更记录写入binlog日志(二进程日志),然后从库中有一个IO线程将主库的binlog日志Copy过来写入中继日志中,从库会从中继日志逐行读取binlog日志,然后执行对应的SQL,这样一来从库的数据就和主库的数据保持一致了。

这里需要留意的是,从库同步数据时是串行而非并行操作的!!!即使在主库上的操作是并行的,那在从库上也是串行执行。所以从库的数据会比主库要慢一些,尤其是在高并发场景下延迟更为严重!
MySQL主从同步延时问题如何解决?
上面讲到了,之所以导致MySQL主从同步存在延迟的原因是从库同步数据时是串行而非并行执行的。
要解决主从同步延迟,有几个可行方案供大家参考:
1、我们可以使用并行复制来处理同步。什么是并行复制呢?并行复制指的就是从库开启多个线程并行读取relay log 中的日志;
2、对实时性要求严格的业务场景,写操作后我们强制从主库中读取;
以上就是我的观点,对于这个问题大家是怎么看待的呢?欢迎在下方评论区交流 ~ 我是科技领域创作者,十年互联网从业经验,欢迎关注我了解更多科技知识!