摘要:
对MySQL慢查询日志进行分析的基本教程?开启慢查询日志mysql>setglobalslow_query_log=1;定义时间SQL查询的超时时间mysql&...
摘要:
对MySQL慢查询日志进行分析的基本教程?开启慢查询日志mysql>setglobalslow_query_log=1;定义时间SQL查询的超时时间mysql&... 对MySQL慢查询日志进行分析的基本教程?
开启慢查询日志
mysql>setglobalslow_query_log=1;
定义时间SQL查询的超时时间
mysql>setgloballong_query_time=0.005;
查看慢查询日志的保存路径
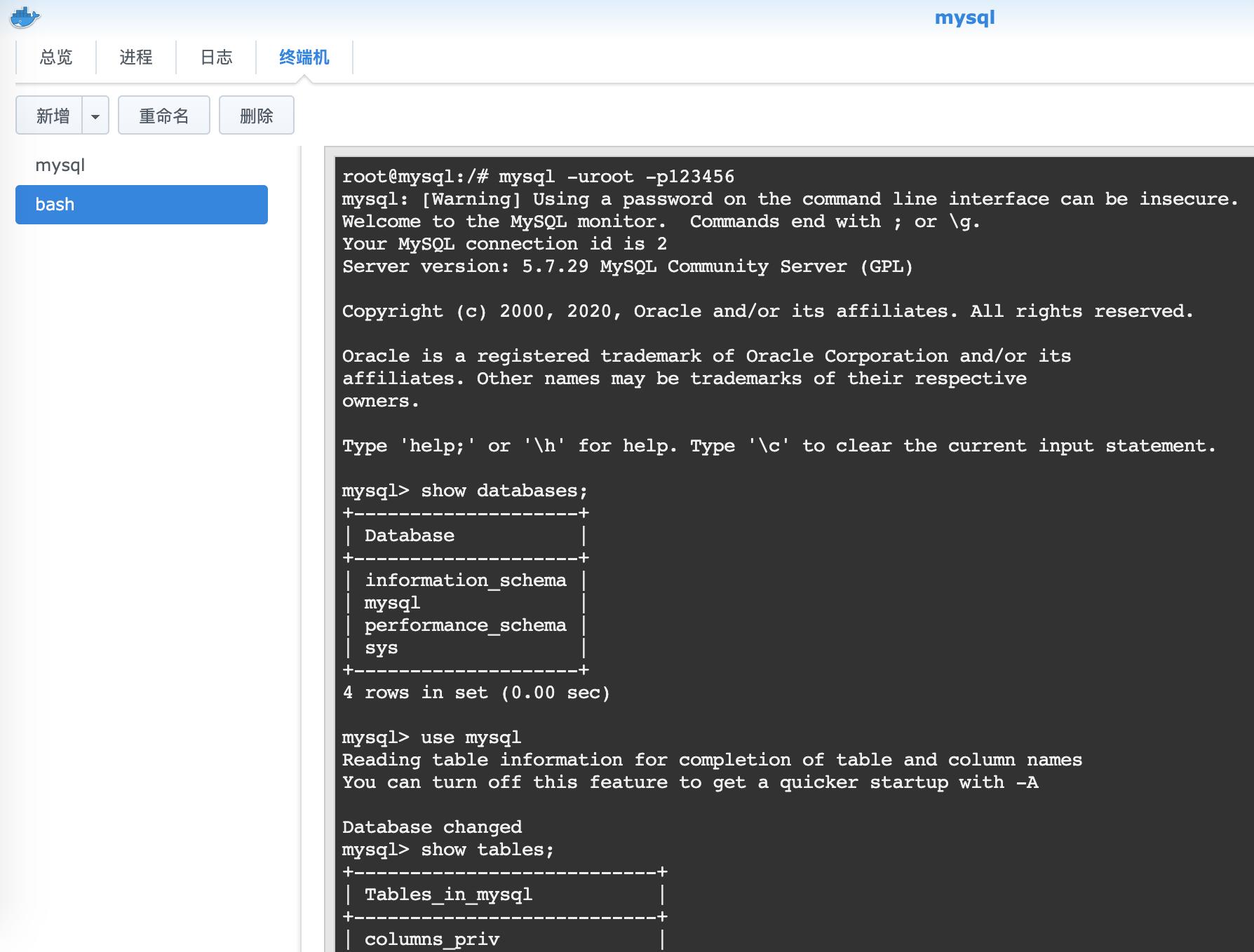
mysql>showglobalvariableslike'slow_query_log_file';
查看慢查询

图片来源:网络
cat/var/log/mysql/slow.log
mysqlinnodbcount(distinct)很慢,怎么优化?
1. 把你的day字段类型改为long型,在页面显示的时候在格式化成自己需要的样式;
2. 在day字段上建立索引;
3. 把ip_4表类型有InnoDB改为MyISAM,如果不需要事物支持的话,建议不要使用InnoDB。
mysql为什么千万级别查询比1000条数据的查询慢?
这是自然规律使然。
形象一点来讲,有人将各一枚硬币分别丢进一碗水里和一口水塘里,然后您要将它们捞出来,哪个任务完成的快?当然是前者了,因为工作量没法比啊! 数据库查询道理也是一样的,数据越多从中检索出记录的速度越慢。你也许会说数据库不是有索引吗?咱不用从头到尾逐条检索呀。没错,有索引数据库引擎可以直奔目标,检索少量数据的时候,1千条记录跟千万条记录比,从中检索出记录的耗时相差无几,但是如果要检索出所有记录的话,两者的系统和时间开销可就不是一个数量级了,后者肯定慢得多。管理一个小仓库跟管理一个巨型仓库的人力、物力开销肯定是不一样的,数据库表查询也同理!mysql中数据量大时超30万,加上order by速度就变慢很多,一般需要0.8秒左右,不加只需要0.01几秒?
那肯定的
ORDERY BY是要对某个字段进行排序的,有人喜欢加索引解决,但是若是对于一个频繁有写操作的表来说,一个索引还好说,要是有多个索引,数据表的大小增加会相当惊人
另上,建议使用InnoDB引挚,有人说这样速度会快很多
对于大数据级的数据库来说,最关键的一步还是要优化好你的SQL,还有就是使用非常规的作法,供参考
1,以牺牲空间换取速度,就是说看能不能进行一些适当的缓存
2,以牺牲速度换取空间,这对于小空间容量的主机可以采用
为什么mysql中delete比insert要慢?
MySQL的默认的调度策略可用总结如下:写入操作优先于读取操作。
对某张数据表的写入操作某一时刻只能发生一次,写入请求按照它们到达的次序来处理。对某张数据表的多个读取操作可以同时地进行。那么 delete相当于先查找再移除,因此必然慢于insert插入~我用mysql客户端访问远程服务器很快,可是在java项目里访问数据就很慢,为啥啊?
可能是网络问题因为 你的这个远程访问应该是在局域网内。而你的java项目现在和数据库服务器不在同一个局域网内,中间就产生了局域网传输数据的效率和互联网传输数据的效率的差异。