摘要:
hive为什么查询速度比mysql慢?Hive相对于MySQL查询速度慢的主要原因包括:1. 数据存储和处理方式:Hive是基于Hadoop分布式文件系统(HDFS)的数据仓库,而...
摘要:
hive为什么查询速度比mysql慢?Hive相对于MySQL查询速度慢的主要原因包括:1. 数据存储和处理方式:Hive是基于Hadoop分布式文件系统(HDFS)的数据仓库,而... hive为什么查询速度比mysql慢?
Hive相对于MySQL查询速度慢的主要原因包括:
1. 数据存储和处理方式:Hive是基于Hadoop分布式文件系统(HDFS)的数据仓库,而MySQL是关系型数据库管理系统(RDBMS)。Hive将数据存储在HDFS中,需要通过MapReduce来处理和查询数据,而MySQL使用基于索引的查询方式,可以更快地检索数据。
2. 数据格式和压缩:Hive默认使用文本格式存储数据,而MySQL使用二进制格式。在查询数据时,文本格式需要进行解析,增加了查询的开销。此外,Hive也支持数据压缩,但压缩和解压缩过程会带来计算开销。
3. 查询优化:Hive是一个批处理框架,适用于大规模数据处理和分析。它执行查询时需要进行多个阶段的MapReduce任务,包括数据读取、数据转换和聚合等,每个阶段都需要进行磁盘IO和网络传输,导致查询速度相对较慢。而MySQL使用了更多的查询优化技术,如索引、查询缓存和预编译等,可以更快地执行查询操作。
4. 数据规模和并行性:由于Hive适用于处理大规模数据集,它通常在大型集群上运行,可以在多个计算节点上并行处理数据。但对于小规模数据集和单个计算节点上的查询,Hive的查询性能可能会受到限制。
总的来说,Hive的设计目标是为了处理大规模数据集的分布式计算,而MySQL则更适用于小规模数据集和在线事务处理。因此,在查询速度方面,MySQL通常会比Hive更快。
一般mysql超过多长时间,会被认为是慢查询?
一般情况下,当MySQL查询的执行时间超过阈值时,会被认为是慢查询。这个阈值可以根据具体的应用需求进行配置,通常设置为几秒钟。超过这个时间的查询可能会对系统性能产生负面影响,因此被认为是慢查询。慢查询可以通过MySQL的慢查询日志进行记录和分析,以便优化查询性能并提高系统的响应速度。
为什么mysql中delete比insert要慢?
MySQL的默认的调度策略可用总结如下:写入操作优先于读取操作。
对某张数据表的写入操作某一时刻只能发生一次,写入请求按照它们到达的次序来处理。对某张数据表的多个读取操作可以同时地进行。那么 delete相当于先查找再移除,因此必然慢于insert插入~10w数据mysql排序很慢么?
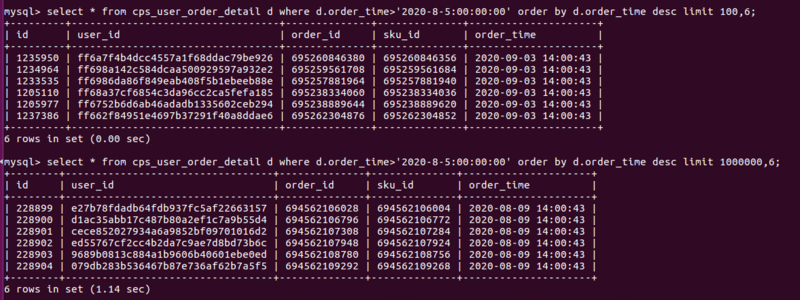
10 万条数据在 MySQL 中进行排序的速度取决于多种因素,例如数据类型、索引、硬件性能等。一般来说,如果数据已经按照需要排序的字段进行了索引,并且硬件性能足够好,那么排序 10 万条数据的速度应该是比较快的。
但是,如果数据没有索引,或者索引不正确,或者硬件性能较差,那么排序 10 万条数据可能会比较慢。在这种情况下,可以考虑优化索引、升级硬件或者使用其他方法来加速排序。
另外,如果需要频繁地对大量数据进行排序,那么可以考虑使用专门的排序算法或者分布式计算来提高排序效率。
mysql select insert速度执行起来有点慢,有没有更效率的查询插入语句命令呢?
Mysql 的select insert语句执行速度慢,首先想到是语句是不是优化,有没有更效率的查询插入语句命令,这个应该是不成立的,DDL和DML的语句都是有固定的语法。
MySQL语句优化-EXPLAIN
EXPLAIN 语句可以被当作 DESCRIBE 的同义词来用,也可以用来获取一个MySQL要执行的 SELECT 语句的相关信息。

语法:
EXPLAIN SELECTselect_options或者EXPLAINtbl_name
EXPLAIN tbl_name 语法和 DESCRIBE tbl_name 或 SHOW COLUMNS FROM tbl_name 一样。
- 当在一个 SELECT 语句前使用关键字 EXPLAIN 时,MYSQL会解释了即将如何运行该 SELECT 语句,它显示了表如何连接、连接的顺序等信息。
MySQL语句优化方法
应尽量避免在 where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描;
应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描;
应尽量避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描;
in 和 not in 也要慎用,否则会导致全表扫描。